The climate dice are loaded: A replication
 (Source: Popovich & Pearce (2017): *[It’s Not Your Imagination. Summers Are Getting Hotter](https://www.nytimes.com/interactive/2017/07/28/climate/more-frequent-extreme-summer-heat.html)*, New York Times)
(Source: Popovich & Pearce (2017): *[It’s Not Your Imagination. Summers Are Getting Hotter](https://www.nytimes.com/interactive/2017/07/28/climate/more-frequent-extreme-summer-heat.html)*, New York Times)
On July 28, 2017, the New York Times published an article by Nadja Popovich and Adam Pearce with the intriguing title "It’s Not Your Imagination. Summers Are Getting Hotter". As the title suggests, the article makes the claim that summers are getting hotter and hotter. The main argument of the article is the visualization depicted above. It shows "how summer temperatures have shifted toward more extreme heat over the past several decades".
This is a very effective visualization because it communicates relatively complicated scientific information (a distribution of temperatures) in an approachable way. All you need to understand is that temperatures move to the right, which means summers get hotter. (The article also features an animated visualization, which shows how the temperature distribution has changed over the decades.). This post replicates the visualization and reflects on the underlying data preparation and data wrangling activities.
What does the visualization show?¶
In a nutshell, the visualization shows that our chances to experience hot weather during summer months are rising. The visualization that the distribution of temperature measurements on Earth's Northern hemisphere during the summer months (more specifically, June, July, and August) shifts toward hotter temperature over the decades.
The visualization displays a probability density functions for each decade since the 1950s. Probability density functions are fairly complicated statistical instruments, when compared to the typical bar charts or scatter plots in most visualizations. However, the reader does not necessarily need to understand the meaning of probability density functions. Instead, the authors use color (blue, orange, and red) to denote colder and hotter temperatures and animations to visualize the change of temperatures:
- The (grey) area represents the base distribution of temperatures. This baseline is calculated from the summer temperature measurements between 1951 to 1980. The colored areas represent the summer temperature distribution between 2005 and 2015.
- As the probability density function shifts to the right, the colored areas change accordingly. For instance, in the initial probability density function, the reader will probably not notice the small dark red area that denotes extreme temperatures. However, in the final probability density function, the dark red area is substantially larger.
- The animation allows the reader to understand the shift of colors as the visualization cycles through the decades.
I encourage you to visit the original article in the New York Times to experience the full effect of the visualization.
Where does the data come from?¶
The article is a consumer-friendly version of visualizations reported in the following research paper that has been published in the Proceedings of the National Academy of Sciences of the United States of America (PNAS):
James Hansen, Makiko Sato, Reto Ruedy (2012): Perception of Climate Change. Proceedings of the National Academy of Sciences, 109(37) E2415-E2423; DOI: 10.1073/pnas.1205276109
The paper offers the fundamental idea for the visualization. While these original visualizations convey the same content, the visualizations have a distinct "scientific" look and feel ;)
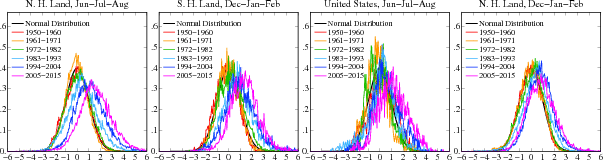 (Source: Hansen et al. (2012): *[Perception of Climate Change](http://www.columbia.edu/~mhs119/PerceptionsAndDice/)*, Columbia University)
(Source: Hansen et al. (2012): *[Perception of Climate Change](http://www.columbia.edu/~mhs119/PerceptionsAndDice/)*, Columbia University)
It is important to note the following characteristics of the data in Hansen et al. 2012:
- The shift in the average temperature is only for the Northern hemisphere.
- The paper uses averaged temperature data of 250km squares.
A replication¶
I replicate the Hansen et al. (2012) using the following steps:
- A replication of the data analysis presented by Hansen et al. (2012)
- A replication of the visualizations created by Hansen et al. (2012)
- An attempt to get as close as possible to the look and feel of the visualization in the New York Times.
Setup¶
We set up our environment to allow multiple outputs for each code cell. Also, we use the magic command to display matplotlib plots in the Jupyter notebook.
# Multiple outputs
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
# Show matplotlib plots inline
%matplotlib inline
import pandas as pd
import numpy as np
We format the display of rows and the number of decimals. (These commands setup Jupyter to my personal preferences. They are not required.)
# Display up to 500 rows at a time
pd.set_option('display.max_rows', 500)
# Format the display of numbers to two decimals
pd.set_option('display.float_format', lambda x: '%.2f' % x)
Furthermore, we use altair to render visualizations.
import altair as alt
#Render altair charts inline
alt.renderers.enable('notebook') # Change this depending on where you run the notebook.
Data¶
The Hansen et al. (2012) paper uses data from the Goddard Institute for Space Studies (GISS), which includes data from the Global Historical Climatology Network (GHCN). Obtaining the GHCN data is surprisingly difficult because it is located on FTP servers, which frequently throw errors (at least on my machine).
However, browsing through the description of the GISS data will lead you to the description of the station data. The station data consists of average monthly temperatures for stations around the globe.
The data for the stations is downloadable here. The data is being continuously updated, so if you download this notebook, some values may be slightly different.
The data is wrapped in a zip file that contains a csv file called step2.v3.csv. The following paper describes the dataset:
Lawrimore, J. H., M. J. Menne, B. E. Gleason, C. N. Williams, D. B. Wuertz, R. S. Vose, and J. Rennie (2011), An overview of the Global Historical Climatology Network monthly mean temperature data set, version 3, J. Geophys. Res., 116, D19121, doi: 10.1029/2011JD016187.
Let's read the data.
raw = pd.read_csv('https://raw.githubusercontent.com/mschermann/loaded_climate_dice/master/step2.v3.csv', header=None)
raw.head()
A quick look at the data reveals three potential issues:
- The data has no header information.
- The data has strange values that initially do not look like temperatures.
- The data clearly has missing values which are denoted as
-9999.
This README file explains the data.
For the fun of it, we nevertheless explore the data and confirm the structure of the data.
Data Exploration¶
Let's interpret, validate, and confirm our understanding of the data.
Column 0¶
The first column seems to be the station identifier. You can confirm this assumption by entering a few station identifiers in the search form here. They check out.
raw[0].sample(3, random_state=123)
Here are the links to the stations above:
- 425004277140 in Scipio, Utah, USA.
- 425002537350 in Hebron, Nebraska, USA.
- 501947140000 in Cootamundra, New South Wales, Australia.
(If you run this notebook on your machine, these values may change because of the underlying data changes).
Column 1¶
The second column seems to contains years. Let's confirm this.
np.sort(raw.iloc[:,1].unique()) # display a sorted list of
# unique values in the second column
This looks very much like years ranging from 1880 to 2018.
Columns 2 to 13¶
Then the file has additional 12 columns. They represent the 12 months of the year. Again, you can confirm this using the search form here.
For instance, the average temperature in January in Santa Cruz, California is 9.8 degrees Celcius (49.6 degrees Fahrenheit). The closest station is 425000479160 in Santa Cruz.
sc = raw[raw[0]==425000479160]
sc[1].min()
sc[1].max()
round((sc[~(sc[2]==-9999)][2].mean())/100, 2) # multiple with 100 to get real temperatures.
The station in Santa Cruz reports an average temperature of 9.83 degrees Celsius in January for the period between 1893 and 2018.
The 12 columns contain the average temperature per month. The values are in hundredths of a degree Celsius. For example, 983 means an average of 9.83 degree Celsius (49.694 degrees Fahrenheit).
-9999 denotes missing values. Again, the README file explains the values (and many more).
(Source: J. H. Lawrimore, M. J. Menne, B. E. Gleason, C. N. Williams, D. B. Wuertz, R. S. Vose, and J. Rennie (2011), [An overview of the Global Historical Climatology Network monthly mean temperature data set, version 3](https://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/2011JD016187), J. Geophys. Res., 116, D19121, doi: [10.1029/2011JD016187](https://doi.org/10.1029/2011JD016187))
Data Preparation¶
With this interpretation, we rename the original file to reflect our interpretation. We read the data as follows:
- Missing values (
na_values) are-9999 - The first column is called
station_id - The second column is called
year - The remaining 12 columns are called
jan,feb,mar,apr,may,jun,jul,aug,sep,oct,nov,dec
data = raw.copy()
data = data.replace(-9999,np.NaN)
data.columns = ['station_id','year',\
'jan','feb','mar','apr',\
'may','jun','jul','aug',\
'sep','oct','nov','dec']
We have a look at the first five rows of the dataset.
data.head()
len(data['station_id'].unique())
The dataset contains temperature information from 5991 stations.
Data Wrangling¶
The Hansen et al. (2012) paper focusses on the summer months only. The paper argues that the shift of the probability density function is more pronounced in the summer months (See charts above).
We focus our data on the three months of summer: June, July, August.
summer = data.loc[:,['station_id', 'year', 'jun', 'jul', 'aug']]
summer.head()
To make our life easier, we drop rows with any missing values.
summer.dropna(inplace=True)
len(summer['station_id'].unique())
Despite removing missing values, we have data for at least one summer for each station.
The probability density functions should represent the full summer. After all, the title of the New York Times article is "Summers Are Getting Hotter". The Hansen et al. (2012) paper is using the mean of the summer months. This is what we do, too.
We create a mean for each row in the summer data frame and store it in a new column called JJA, which stands for
- June,
- July,
- August.
summer['JJA'] = summer[['jun', 'jul', 'aug']].mean(axis=1) #generate a mean for each row
We do not need the columns for the individual months any longer, so we drop them.
summer.drop(['jun', 'jul', 'aug'], axis=1, inplace=True)
The individual stations are all around the globe. A station near the equator will measure vastly different temperatures than a station near the south pole. However, we are only interested in changes in the mean temperature over time.
Thus, we standardize the JJA column by calculating the z-score for each temperature measurement. You calculate z-scores by subtracting the mean from each value and then divide by the standard deviation. The result of this process are values with a mean of 0 and a standard deviation of 1.
A first attempt¶
summer_fa = summer.copy()
summer_fa['z'] = summer.groupby('station_id')['JJA'].\
transform(lambda x: (x - x.mean()) / x.std())
A quick look at the summer data shows that we now have the z-score for each summer and station.
summer_fa.head()
As expected the mean for each station is 0 and the standard deviation is 1.
summer_fa.groupby('station_id')['z'].mean().sample(5, random_state=123)
summer_fa.groupby('station_id')['z'].std().sample(5, random_state=123)
round(summer_fa['z'].mean(), 2)
round(summer_fa['z'].std(), 2)
We use the hist function to visualize the histogram (a visual representation of the probaility density functions). Since the z-score is a continuous measure, we create one hundred bins.
summer_fa['z'].hist(bins=1000, histtype='step', density=True);

This looks very much like the end result we would like to have. However, currently, all the temperatures are averages across the whole period. We do not have the baseline yet. The original idea by Hansen et al. (2012) is to use the temperatures of the years between 1951 and 1980 as the baseline.
Understanding the distribution of data across the time periods¶
Before we establish the baseline, we need to have a clear understanding of what subsets of the data are relevant for the baseline. In general, we have three subsets:
- Data prior to the baseline suggested by Hansen et al. (2012)
- Data of the baseline between 1951 and 1980.
- Data after the baseline.
len(summer[summer['year']<=1950]['station_id'].unique())
len(summer[(summer['year']>1950) & (summer['year']<1981)]['station_id'].unique())
len(summer[summer['year']>=1981]['station_id'].unique())
- 3884 stations report data from prior to the baseline.
- 5784 stations report data on the baseline period. This is an increase by 1900 stations compared to prior to the baseline.
- 5151 stations report data beyond the baseline period. This is a decrease by 633 stations compared to the baseline.
prior_baseline = summer[summer['year']<=1950]['station_id']
baseline = summer[(summer['year']>1950) & (summer['year']<1981)]['station_id']
beyond_baseline = summer[summer['year']>=1981]['station_id']
We analyze the distribution of stations across the timeperiod.
# Stations that only appear in the prior data
only_prior = prior_baseline[(~prior_baseline.isin(baseline)) \
& (~prior_baseline.isin(beyond_baseline))].unique()
# Stations that appear in prior and(?) in beyond
resurrected_prior = prior_baseline[(~prior_baseline.isin(baseline)) \
& (prior_baseline.isin(beyond_baseline))].unique()
# Stations that only appear in the baseline
only_base = baseline[(~baseline.isin(prior_baseline)) \
& (~baseline.isin(beyond_baseline))].unique()
# Stations that only appear in the beyond data
only_beyond = beyond_baseline[(~beyond_baseline.isin(prior_baseline)) \
& (~beyond_baseline.isin(baseline))].unique()
# Stations that only appear in prior and baseline
prior_and_base = prior_baseline[(prior_baseline.isin(baseline)) \
& (~prior_baseline.isin(beyond_baseline))].unique()
# Stations that only appear in baseline and beyond data
base_and_beyond = baseline[(baseline.isin(beyond_baseline)) \
& (~baseline.isin(prior_baseline))].unique()
# Stations that appear in prior, baseline, and beyond
prior_and_base_and_beyond = prior_baseline[(prior_baseline.isin(baseline)) \
& (prior_baseline.isin(beyond_baseline))].unique()
#len(only_prior)
#len(resurrected_prior)
#len(only_base)
#len(only_beyond)
#len(prior_and_base)
#len(base_and_beyond)
#len(prior_and_base_and_beyond)
(len(only_prior)+
len(resurrected_prior)+
len(only_base)+
len(only_beyond)+
len(prior_and_base)+
len(base_and_beyond)+
len(prior_and_base_and_beyond))
The following table shows the distribution of stations over the relevant periods (prior to baseline, during baseline, beyond baseline).
| Number of Stations | Percentage | Description |
|---|---|---|
| 131 | 2.19% | Stations that report data only prior to the baseline. |
| 7 | 0.12% | Stations that report data prior to and beyond the baseline but not on the baseline (seems like they have been resurrected). |
| 158 | 2.64% | Stations that report data only on the baseline. |
| 69 | 1.15% | Stations that report data only beyond the baseline. |
| 551 | 9.12% | Stations that report data prior to the baseline and on the baseline. |
| 1880 | 31.38% | Stations that report data on the baseline and beyond |
| 3195 | 53.33% | Stations that report data on all three periods |
| 5991 | ~ 100% | Total |
Establishing the baseline¶
Currently, the z-scores are calculated using the full dataset. We establish the baseline by calculating the mean and the standard deviation using station data from the time period of 1951 to 1980.
We create a new data set that only contains the baseline data. We copy the summer data, group the data by the station_id, and use the agg function to create the required statistical information mean and standard deviation. Additionally, we create the count to make sure that the mean and standard deviation was derived from a decent number of measurements. We reset the index to obtain a standard data frame.
base = summer[(summer['year']>1950) & (summer['year']<1981)].copy().\
groupby('station_id')['JJA'].agg(['count','mean','std']).reset_index()
len(summer[(summer['year']>1950)]['station_id'].unique()) - \
len(base['station_id'].unique())
We have 76 stations that offer no data on the base period. These are the 7 "resurrected" stations and the 69 stations installed after 1980 (See the table above).
Let's have a look at the result.
base.head()
Now, we add the baseline count, mean, and standard deviation to the original summer data.
summer_base = pd.merge(summer, base, how='left', \
left_on='station_id', right_on='station_id')
summer_base[['count','mean','std']].describe()
len(summer_base['station_id'].unique()) # number of all stations
len(summer_base[summer_base['count'].notnull()]['station_id'].unique()) # stations with baseline
len(summer_base[summer_base['std'].notnull()]['station_id'].unique()) # full data
The data makes sense. The minimum mean temperature is -66.86 degrees Celsius in Vostok on Antarctica. The maximum mean temperature is 37.28 degrees Celcius in Sibi in Pakistan.
The number of stations also checks out. 5784 of the 5991 stations report data on the baseline. We lose 18 (5784-5766) stations because it is not possible to calculate the standard deviation. These stations have only 1 year within the baseline (either 1951 or 1980).
len(summer_base[(summer_base['mean'].notnull()) & \
(summer_base['std'].isnull())]['station_id'].unique())
summer_base.dropna(inplace=True) # removes stations without standard deviation.
Calculating the z-score is now very easy. We simply take the JJA, subtract the mean and divide by std.
summer_base['z_base'] = (summer_base['JJA']-summer_base['mean'])/summer_base['std']
summer_base.head()
summer_base['z_base'].describe()
The min and max values show that there are some outliers.
These outliers appear in the dataset because we have calculated the mean and the standard deviation only on the baseline time period. That means a station that began operation in 1978 only has three observations even though it may have far more observations on the complete dataset. See the following example.
summer_base[abs(summer_base['z_base'])>15]['station_id'].unique()
base[base['station_id']==632133630000]
summer_base[summer_base['station_id']==632133630000]
We ignore them for now by restricting the data to +/- 5 standard deviations.
sb = summer_base[abs(summer_base['z_base'])<5].copy()
len(sb['station_id'].unique())
The baseline histograms¶
Let's have a look at the histogram, again.
sb[sb['year']<1981]['z_base'].hist(bins=1000, histtype = 'step', density=True);

If we now look at the data since 2000, we notice the shift to the right. This looks promising.
sb[sb['year']>=1981]['z_base'].hist(bins=1000, histtype = 'step', density=True);

Include the decades¶
We add a column to the data that contains the decade starting with 1951, 1961, 1971 and so on.
#https://stackoverflow.com/questions/48856982/divide-data-by-decade-then-plot-it-seaborn-box-and-whisker
sb['decade'] = (sb['year'] // 10) * 10 + 1
sb.loc[(sb['year'] % 10) == 0, 'decade'] = sb['decade'] - 10
Let's have a look at the data.
sb.head()
Let's plot the data per decade.
sb[sb['decade']==1951]['z_base'].hist(bins=200, histtype = 'step', label='1951', density=True)
sb[sb['decade']==1961]['z_base'].hist(bins=200, histtype = 'step', label='1961', density=True)
sb[sb['decade']==1971]['z_base'].hist(bins=200, histtype = 'step', label='1971', density=True)
sb[sb['decade']==1981]['z_base'].hist(bins=200, histtype = 'step', label='1981', density=True)
sb[sb['decade']==1991]['z_base'].hist(bins=200, histtype = 'step', label='1991', density=True)
sb[sb['decade']==2001]['z_base'].hist(bins=200, histtype = 'step', label='2001', density=True)
sb[sb['decade']==2011]['z_base'].hist(bins=200, histtype = 'step', label='2011', density=True).legend(loc='upper right');

That is very close to the results in Hansen et al. (2012). It is important to note that we use the complete station data (Not just the data from the Northern hemisphere as in the two articles.)
Focus on the Northern hemisphere¶
The Goddard Institute for Space Studies (GISS) also provides more details on the stations here. This is a text file(!) with very problematic formatting. Simply reading the file does not work. We need a fixed-width reader. Lucky us, Pandas provides one.
colspecs = [(0,11),(12,42),(43,49),(50,57)]
stations = pd.read_fwf('https://raw.githubusercontent.com/mschermann/loaded_climate_dice/master/v3.temperature.inv.txt', colspecs=colspecs, names=['station_id', 'name', 'lat', 'lon'], header=None, index_col=0, skiprows=40).reset_index()
stations.sample(10, random_state=123)
len(stations)
len(sb['station_id'].unique())
Strangely, the station ids from the temperature dataset have an additional zero at the end, which we need to remove.
sb['station_id'].sample(10, random_state=123)
#https://stackoverflow.com/questions/33034559/how-to-remove-last-the-two-digits-in-a-column-that-is-of-integer-type
sb['station_id'] = sb['station_id'].astype(str).str[:-1].astype(np.int64)
We have more stations than being used in our temperature dataset. We extract the stations that are in temperature dataset.
stations = stations[stations['station_id'].isin(sb['station_id'])]
len(stations)
np.sort(stations['lat'].unique())
np.sort(stations['lon'].unique())
Now, we can merge the station information with the weather information.
loc_sb = pd.merge(sb, stations, how='left', left_on='station_id', right_on='station_id')
Let's have a look and drop all rows with missing values.
loc_sb.head()
loc_sb.dropna(inplace=True)
len(loc_sb['station_id'].unique())
Next, we need to filter the information so that we only get the Northern hemisphere. The station information explains:
Lat =latitude in degrees, negative = South of Equator
nh_loc_sb = loc_sb[loc_sb['lat']>0].copy()
sh_loc_sb = loc_sb[loc_sb['lat']<0].copy()
len(nh_loc_sb['station_id'].unique())
len(sh_loc_sb['station_id'].unique())
Roughly 83% of all stations are in the Northern hemisphere.
Histograms by decade¶
In the decades leading up to the base period, the temperatures meander around the mean.
nh_loc_sb[nh_loc_sb['decade']==1881]['z_base'].hist(bins=100, histtype = 'step', label='1881', density=True)
nh_loc_sb[nh_loc_sb['decade']==1891]['z_base'].hist(bins=100, histtype = 'step', label='1891', density=True)
nh_loc_sb[nh_loc_sb['decade']==1901]['z_base'].hist(bins=100, histtype = 'step', label='1901', density=True)
nh_loc_sb[nh_loc_sb['decade']==1911]['z_base'].hist(bins=100, histtype = 'step', label='1911', density=True)
nh_loc_sb[nh_loc_sb['decade']==1921]['z_base'].hist(bins=100, histtype = 'step', label='1921', density=True)
nh_loc_sb[nh_loc_sb['decade']==1931]['z_base'].hist(bins=100, histtype = 'step', label='1931', density=True)
nh_loc_sb[nh_loc_sb['decade']==1941]['z_base'].hist(bins=100, histtype = 'step', label='1941', density=True).legend(loc='upper right');

nh_loc_sb[nh_loc_sb['decade']==1951]['z_base'].hist(bins=100, histtype = 'step', label='1951', density=True)
nh_loc_sb[nh_loc_sb['decade']==1961]['z_base'].hist(bins=100, histtype = 'step', label='1961', density=True)
nh_loc_sb[nh_loc_sb['decade']==1971]['z_base'].hist(bins=100, histtype = 'step', label='1971', density=True)
nh_loc_sb[nh_loc_sb['decade']==1981]['z_base'].hist(bins=100, histtype = 'step', label='1981', density=True)
nh_loc_sb[nh_loc_sb['decade']==1991]['z_base'].hist(bins=100, histtype = 'step', label='1991', density=True)
nh_loc_sb[nh_loc_sb['decade']==2001]['z_base'].hist(bins=100, histtype = 'step', label='2001', density=True)
nh_loc_sb[nh_loc_sb['decade']==2011]['z_base'].hist(bins=100, histtype = 'step', label='2011', density=True).legend(loc='upper right');

The results for the Northern hemisphere are almost identical to our result above. Also, the results are almost identical to the Hansen et al. (2012) paper (first chart on the left):
(Source: Hansen et al. (2012): *[Perception of Climate Change](http://www.columbia.edu/~mhs119/PerceptionsAndDice/)*, Columbia University)
The Southern hemisphere¶
sh_loc_sb[sh_loc_sb['decade']==1881]['z_base'].hist(bins=100, histtype = 'step', label='1881', density=True)
sh_loc_sb[sh_loc_sb['decade']==1891]['z_base'].hist(bins=100, histtype = 'step', label='1891', density=True)
sh_loc_sb[sh_loc_sb['decade']==1901]['z_base'].hist(bins=100, histtype = 'step', label='1901', density=True)
sh_loc_sb[sh_loc_sb['decade']==1911]['z_base'].hist(bins=100, histtype = 'step', label='1911', density=True)
sh_loc_sb[sh_loc_sb['decade']==1921]['z_base'].hist(bins=100, histtype = 'step', label='1921', density=True)
sh_loc_sb[sh_loc_sb['decade']==1931]['z_base'].hist(bins=100, histtype = 'step', label='1931', density=True)
sh_loc_sb[sh_loc_sb['decade']==1941]['z_base'].hist(bins=100, histtype = 'step', label='1941', density=True).legend(loc='upper right');

sh_loc_sb[sh_loc_sb['decade']==1951]['z_base'].hist(bins=100, histtype = 'step', label='1951', density=True)
sh_loc_sb[sh_loc_sb['decade']==1961]['z_base'].hist(bins=100, histtype = 'step', label='1961', density=True)
sh_loc_sb[sh_loc_sb['decade']==1971]['z_base'].hist(bins=100, histtype = 'step', label='1971', density=True)
sh_loc_sb[sh_loc_sb['decade']==1981]['z_base'].hist(bins=100, histtype = 'step', label='1981', density=True)
sh_loc_sb[sh_loc_sb['decade']==1991]['z_base'].hist(bins=100, histtype = 'step', label='1991', density=True)
sh_loc_sb[sh_loc_sb['decade']==2001]['z_base'].hist(bins=100, histtype = 'step', label='2001', density=True)
sh_loc_sb[sh_loc_sb['decade']==2011]['z_base'].hist(bins=100, histtype = 'step', label='2011', density=True).legend(loc='upper right');

The results for the Southern hemisphere also show the shift to the right. However, the shift is far less pronounced. Also, we have far fewer stations for the Southern hemisphere.
Correcting for Data Biases¶
Hansen et al. (2012) note two characteristics of the results. First, as clearly visible, the temperature moves to the right. Second and more subtle, the distribution of temperatures becomes wider and flatter. Thus, Hansen et al. (2012) argue that the variance of the temperatures increases, too. However, this interpretation is not without challenges.
A response article to Hansen et al. (2012) challenges the second interpretation, the increase in variance, of the data:
Andrew Rhines, Peter Huybers (2013): Frequent summer temperature extremes reflect changes in the mean, not the variance, Proceedings of the National Academy of Sciences, 110(7) E546; DOI: 10.1073/pnas.1218748110
The authors argue that the data is biased towards higher variance for the following reasons:
- Normalizing time series with the standard deviation of the baseline only introduces a bias because "the mean temperature of individual time series generally differs from zero during the later period". This difference in the means across the time series increases the variance.
- Trends in the time series also increase the variance.
- We have fewer stations in the dataset for later periods. Recall that 5784 stations report data on the baseline period but only 5151 report data beyond the baseline.
The original variance ratio between baseline and the time period 1981-2010 is 1.88. Rhines and Huybers (2013) suggest to debias the data in the following way:
- Removing the sample means independently will reduce the ratio to 1.49.
- Removing differences in the spatial variance between the baseline and the time period 1981-2010 will reduce the ratio to 1.24
- Accounting for the increase in errors due to fewer stations will reduce the ratio to 0.98.
Before we replicate these approaches to debiasing, let's have a closer look at the data from the perspective of Rhines and Huybers (2013).
Comparing the variances¶
First, we look at the variances in the various time periods. We use the data from the Northern hemisphere.
round(nh_loc_sb[(nh_loc_sb['year']>1950) & (nh_loc_sb['year']<1981)]['z_base'].mean(), 2)
round(nh_loc_sb[(nh_loc_sb['year']>1950) & (nh_loc_sb['year']<1981)]['z_base'].var(), 2)
round(nh_loc_sb[(nh_loc_sb['year']>=1981) & (nh_loc_sb['year']<2011)]['z_base'].mean(), 2)
round(nh_loc_sb[(nh_loc_sb['year']>=1981) & (nh_loc_sb['year']<2011)]['z_base'].var(), 2)
round(nh_loc_sb[(nh_loc_sb['year']>=1981)]['z_base'].mean(), 2)
round(nh_loc_sb[(nh_loc_sb['year']>=1981)]['z_base'].var(), 2)
For the baseline, the mean is 0 (as expected) and the variance is close to 1 (it is not exactly 1 because we removed stations with standard deviations with an absolute value of larger than 5. These outliers will have a significant effect on the variance.
For the time period 1981 to 2010, the mean shifts to the right and the variance increases, too. The variance is noticeably different from Rhines and Huybers (2013) because of the removal of outliers.
If we extend the later period to all available data beyond the baseline, the mean continues to shifts to the right and the variance also increases.
We can also have a look at how the mean and the variance shifts over the decades.
mean_var = nh_loc_sb.groupby('decade')['z_base'].agg({'mean','var'}).reset_index()
mean_var['decade'] = mean_var['decade'].astype(str)
#https://altair-viz.github.io/gallery/falkensee.html
mean = alt.Chart(mean_var).mark_line(color='#333').encode(
x=alt.X('decade:T', axis=alt.Axis(title='Decade', format='%Y')),
y=alt.Y('mean', axis=alt.Axis(title='Deviation from the baseline temperature')),
).properties(
width=250,
height=200
)
var = alt.Chart(mean_var).mark_line(color='#333').encode(
x=alt.X('decade:T', axis=alt.Axis(title='Decade', format='%Y')),
y=alt.Y('var', axis=alt.Axis(title='Variance of the deviation'))
).properties(
width=250,
height=200
)
areas = alt.pd.DataFrame([{
'start': '1951',
'end': '1981',
'period': 'Baseline'
},
{
'start': '1981',
'end': '2011',
'period': 'Comparison'
}])
rect = alt.Chart(areas).mark_rect().encode(
x='start:T',
x2='end:T',
color= alt.Color('period:N', scale=alt.Scale(domain=['Baseline', 'Comparison'],
range=['#aec7e8', '#ffbb78'])),
)
(rect + mean) | (rect + var)

We see that the deviation of from the baseline temperature (left chart) changes from negative to positive values. There are two noticeable spikes in the data. One around 1890 and the other around 1930. Browsing Wikipedia reveals that at least for the United States, these spikes correspond to documented heat waves in 1896 and 1936. Not that these explain the spikes but at least the data is consistent with the events. (Remember the data shows the summer months only.)
The variance does not have the same visual trend as the mean temperature.
stations_per_decade = nh_loc_sb.groupby('decade')['station_id'].nunique().reset_index()
stations_per_decade['decade'] = stations_per_decade['decade'].astype(str)
var = alt.Chart(mean_var).mark_line(color='#333').encode(
x=alt.X('decade:T', axis=alt.Axis(title='Decade', format='%Y')),
y=alt.Y('var', axis=alt.Axis(title='Variance of the deviation'))
).properties(
width=250,
height=200
)
no_stations = alt.Chart(stations_per_decade).mark_line(color='orange').encode(
x=alt.X('decade:T', axis=alt.Axis(title='Decade', format='%Y')),
y=alt.Y('station_id', axis=alt.Axis(title='Number of stations'))
).properties(
width=250,
height=200
)
alt.layer(var,no_stations).resolve_scale(y='independent')

The black line shows the variance for each decade as a ratio of the baseline. The orange line shows the number of stations reporting temperature measurements for each decade. The more stations report data, the lower is the variance. Intuitively, this makes sense and is in line with the third argument, the measurement errors, by Rhines and Huybers (2013).
Now that we have a relatively good understanding of the biases in the data, let's correct the data for the biases.
Removing the sample means independently¶
c_s = summer_base.copy()
We generate the additional information for the first correction suggested by Rhines and Huybers (2013), which means that we calculate the standard deviation for the comparison periods (1981 to 2010 and 1981 to today) separately. We then calculate the z-scores using the baseline mean but the standard deviations from the comparison periods.
sd_2010 = summer[(summer['year']>=1981) & (summer['year']<2011)].copy().\
groupby('station_id')['JJA'].agg(['count','mean','std']).reset_index()
sd_today = summer[(summer['year']>=1981)].copy().\
groupby('station_id')['JJA'].agg(['count','mean','std']).reset_index()
c_s_complete = pd.merge(c_s, sd_2010, how='left', \
left_on='station_id', right_on='station_id', suffixes=('_base', '_2010'))
c_s_complete = pd.merge(c_s_complete, sd_today, how='left', \
left_on='station_id', right_on='station_id', suffixes=('_2010', '_today'))
c_s_complete['z_2010'] = (c_s_complete['JJA']-c_s_complete['mean_base'])/c_s_complete['std_2010']
c_s_complete['z_today'] = (c_s_complete['JJA']-c_s_complete['mean_base'])/c_s_complete['std']
c_s_complete.head()
#https://stackoverflow.com/questions/48856982/divide-data-by-decade-then-plot-it-seaborn-box-and-whisker
c_s_complete['decade'] = (c_s_complete['year'] // 10) * 10 + 1
c_s_complete.loc[(c_s_complete['year'] % 10) == 0, 'decade'] = c_s_complete['decade'] - 10
c_s_complete['station_id'] = c_s_complete['station_id'].astype(str).str[:-1].astype(np.int64)
loc_c_s_complete = pd.merge(c_s_complete, stations, how='left', left_on='station_id', right_on='station_id')
nh_c = loc_c_s_complete[loc_c_s_complete['lat']>0].copy()
nh_c = nh_c[abs(nh_c['z_base'])<5].copy()
nh_c = nh_c[abs(nh_c['z_2010'])<5].copy()
nh_c = nh_c[abs(nh_c['z_today'])<5].copy()
nh_c.dropna(inplace=True)
round(nh_c[(nh_c['year']>1950) & (nh_c['year']<1981)]['z_base'].mean(), 2)
round(nh_c[(nh_c['year']>1950) & (nh_c['year']<1981)]['z_base'].var(), 2)
round(nh_c[(nh_c['year']>=1981) & (nh_c['year']<2011)]['z_2010'].mean(), 2)
round(nh_c[(nh_c['year']>=1981) & (nh_c['year']<2011)]['z_2010'].var(), 2)
round(nh_c[(nh_c['year']>=1981)]['z_today'].mean(), 2)
round(nh_c[(nh_c['year']>=1981)]['z_today'].var(), 2)
Calculating the z-scores with the period-specific standard deviations reduced the variance significantly. For the comparison period 1981-2010 we have a variance of 1.23. For the comparison period 1981-today we have a variance of 1.24.|
nh_c[(nh_c['year']>1950) & (nh_c['year']<1981)]['z_base'].\
hist(bins=100, histtype = 'step', label='1951-1980', density=True)
nh_c[(nh_c['year']>=1981) & (nh_c['year']<2011)]['z_2010'].\
hist(bins=100, histtype = 'step', label='1981-2010', density=True)
nh_c[(nh_c['year']>=1981)]['z_today'].\
hist(bins=100, histtype = 'step', label='1981-today', density=True).legend(loc='upper right');

The shapes of the distributions of temperatures for the three periods look very similar now.
Correcting the data for spatial variance¶
Spatial variance may have been introduced because the temperatures were measured at different spatial locations.
This is the easiest corrections because it is also accounted for. The Hansen et al. (2012) paper uses temperature data in a 250km grid, which means that the measurements of all the stations within a given grid have been averaged.
Here, we use the actual station data. Thus, our analysis does not suffer from this bias. Hence, our corrected variance of 1.24 is the same as reported by Rhines and Huybers (2013) after they have corrected for the spatial variance.
Correcting for the reduced number of stations¶
A decrease in stations that measure temperatures means that the density of stations in each of the 250km grids decreases and in turn, the likelihood of measurement errors increases. Rhines and Huybers (2013) argue that the measurement error is 1 degree Celsius in each grid. They correct the data by multiplying the error with the ratio of stations available in the baseline and comparison periods.
Since we use the fine-granular station data, we can create the subset of stations that report temperatures for both the baseline and the comparison periods. Of course, we also need to apply the correction for the normalization.
all_time = summer[summer['station_id'].isin(prior_and_base_and_beyond)].copy()
len(all_time['station_id'].unique())
We use the data of 3,195 stations. These stations report across the whole timeframe.
at_base = all_time[(all_time['year']>1950) & (all_time['year']<1981)].copy().\
groupby('station_id')['JJA'].agg(['count','mean','std']).reset_index()
at_sd_2010 = all_time[(all_time['year']>=1981) & (all_time['year']<2011)].copy().\
groupby('station_id')['JJA'].agg(['count','mean','std']).reset_index()
at_sd_today = all_time[(all_time['year']>=1981)].copy().\
groupby('station_id')['JJA'].agg(['count','mean','std']).reset_index()
at = pd.merge(all_time, at_base, how='left', \
left_on='station_id', right_on='station_id')
at = pd.merge(at, at_sd_2010, how='left', \
left_on='station_id', right_on='station_id', suffixes=('_base', '_sd_2010'))
at = pd.merge(at, at_sd_today, how='left', \
left_on='station_id', right_on='station_id', suffixes=('_sd_2010', '_sd_today'))
at['z_base'] = (at['JJA']-at['mean_base'])/at['std_base']
at['z_2010'] = (at['JJA']-at['mean_base'])/at['std_sd_2010']
at['z_today'] = (at['JJA']-at['mean_base'])/at['std']
at['decade'] = (at['year'] // 10) * 10 + 1
at.loc[(at['year'] % 10) == 0, 'decade'] = at['decade'] - 10
at['station_id'] = at['station_id'].astype(str).str[:-1].astype(np.int64)
loc_at = pd.merge(at, stations, how='left', left_on='station_id', right_on='station_id')
nh_at = loc_at[loc_at['lat']>0].copy()
nh_at = nh_at[abs(nh_at['z_base'])<5].copy()
nh_at = nh_at[abs(nh_at['z_2010'])<5].copy()
nh_at = nh_at[abs(nh_at['z_today'])<5].copy()
nh_at.dropna(inplace=True)
round(nh_at[(nh_at['year']>1950) & (nh_at['year']<1981)]['z_base'].mean(), 2)
round(nh_at[(nh_at['year']>1950) & (nh_at['year']<1981)]['z_base'].var(), 2)
round(nh_at[(nh_at['year']>=1981) & (nh_at['year']<2011)]['z_2010'].mean(), 2)
round(nh_at[(nh_at['year']>=1981) & (nh_at['year']<2011)]['z_2010'].var(), 2)
round(nh_at[(nh_at['year']>=1981)]['z_today'].mean(), 2)
round(nh_at[(nh_at['year']>=1981)]['z_today'].var(), 2)
The difference in the variance is further reduced but not to the extent that Rhines and Huyber (2013) suggest.
nh_at[(nh_at['year']>1950) & (nh_at['year']<1981)]['z_base'].\
hist(bins=100, histtype = 'step', label='1951-1980', density=True)
nh_at[(nh_at['year']>=1981) & (nh_at['year']<2011)]['z_2010'].\
hist(bins=100, histtype = 'step', label='1981-2010', density=True)
nh_at[(nh_at['year']>=1981)]['z_today'].\
hist(bins=100, histtype = 'step', label='1981-today', density=True).legend(loc='upper right');

We test whether there is a significant difference in the variance. We use Brown and Forsythe's (174) test for homogeneity of variance.
import scipy.stats as sc
b_2010 = sc.levene(nh_at[(nh_at['year']>1950) & (nh_at['year']<1981)]['z_base'],\
nh_at[(nh_at['year']>=1981) & (nh_at['year']<2011)]['z_2010'], \
center='median')
b_2010
b_today = sc.levene(nh_at[(nh_at['year']>1950) & (nh_at['year']<1981)]['z_base'],\
nh_at[(nh_at['year']>=1981)]['z_today'], center='median')
b_today
The difference in variance is significant for both comparison periods. Despite the reduction in the variance due to the bias corrections, the remaining variance in the comparison periods is still significantly different from the baseline period. In conclusion, it seems that Rhines and Huyber (2013) are correct when pointing out the biased variance but Hansen et al. (2012) are still correct in their assessment that both the mean and the variance change.
Interestingly, the question of whether the variance is changing appears to be an open question in the literature. The following article offers a quick summary of the various positions on the issue:
Alexander and Perkins (2013): Debate heating up over changes in climate variability. Environmental Research Letters (8:2013). DOI: 10.1088/1748-9326/8/4/041001
Data Wrangling for further processing¶
The dataset is very large. Let's condense it for further visualization work:
- To display the histograms, we need the z_scores and the decade.
- We only need the data since 1951.
nh_hist_data = nh_at[nh_at['decade']>1941][['z_base', 'z_2010', 'z_today' ,'decade']].copy()
nh_h_b = nh_hist_data[(nh_hist_data['decade']>=1951) &\
(nh_hist_data['decade']<1981)][['z_base', 'decade']]
nh_h_b.rename(columns={"z_base": "z"}, inplace=True)
nh_h_t = nh_hist_data[(nh_hist_data['decade']>=1981)][['z_today', 'decade']]
nh_h_t.rename(columns={"z_today": "z"}, inplace=True)
nh_hist = nh_h_b.append(nh_h_t, ignore_index=True)
nh_hist_c = nh_hist.groupby(['decade', pd.cut(nh_hist['z'], 200)])['z'].\
agg(['count']).reset_index()
For better visualization, we are only interested in the left value of the interval of each bin.
nh_hist_c['z'] = nh_hist_c['z'].apply(lambda x: x.left)
nh_hist_c['z'] = nh_hist_c['z'].astype(np.float64)
nh_hist_c.head()
nh_hist_c['d'] = nh_hist_c.groupby('decade')['count'].transform(lambda x: x.sum())
nh_hist_c['d'] = nh_hist_c['count']/nh_hist_c['d']
nh_hist_c.head()
Final visualization¶
base = alt.Chart(nh_hist_c[nh_hist_c['decade']<1981]).mark_area(color='lightgrey').encode(
x = alt.X('z'),
y = alt.Y('d'),
detail='decade'
)
today = alt.Chart(nh_hist_c[nh_hist_c['decade']>2001]).mark_area(opacity=0.7, color='orange').encode(
x = alt.X('z', axis=alt.Axis(title=None, grid=False, ticks=False, labels=False)),
y = alt.Y('d', axis=alt.Axis(title=None, grid=False, ticks=False, labels=False)),
detail='decade',
)
base + today

We have removed all the axis labels to let the data speak for itself. Obviously, this is just a quick attempt to replicate the visualization itself. The New Times version has comprehensive annotations that help to interpret the visualization. This requires a visualization framework that is more powerful in developing custom visualizations (e.g., D3.js). I will address this in a future post.
However, when comparing our version with the version in the New York Times, we notice that the shift in the mean is similar but the difference in the general shape of the distributions is far less pronounced.
Final Thoughts¶
Replicating the original visualizations of the Hansen et al. (2012) paper was relatively easy. Correcting the underlying data for the biases as recommended by Rhines and Huyber (2013) was far more difficult because we had to interpret the recommendations. This highlights the importance of publishing code and data (e.g., as Jupyter files). Then, everyone can understand the process from raw data to results to visualization.
The effect of the recommended corrections to the data attenuates the implications of the data. While the shift toward higher temperatures seems to be clear, the debate is still open on whether we also have more extreme weather (temperatures in the tails of the distribution). This highlights one of the biggest challenges in data analytics: without a deep understanding of the data and its limitations, you cannot derive robust implications (The analysis above is just a very superficial attempt!).
Our analysis also highlights that data preparation, data wrangling, and robustness checks take up most of the time and effort. The final result does not communicate the amount of work that went into. Thus, it is very important to be clear about the objectives of a data analytics product. If you just want to explore a dataset, quick and dirty is enough, if you want to inform your paying audience, you need considerable more resources (as evidenced by the New York Times article). If you want to inform political decisions and investments into the fight against climate change, you need the combined earnest work of countless researchers.
Literature¶
- Alexander and Perkins (2013): Debate heating up over changes in climate variability. Environmental Research Letters (8:2013). DOI: 10.1088/1748-9326/8/4/041001
- Hansen, Sato, Ruedy (2012): Perception of Climate Change. Proceedings of the National Academy of Sciences, 109(37) E2415-E2423; DOI: 10.1073/pnas.1205276109
- Rhines and Huybers (2013): Frequent summer temperature extremes reflect changes in the mean, not the variance, Proceedings of the National Academy of Sciences, 110(7) E546; DOI: 10.1073/pnas.1218748110
This project (including the data as of October 10, 2018) is available at https://github.com/mschermann/loaded_climate_dice.